Low-Power Folded Tree Architecture for DSP Applications
| ✅ Paper Type: Free Essay | ✅ Subject: Computer Science |
| ✅ Wordcount: 1954 words | ✅ Published: 27 Sep 2017 |
Low-Power Folded Tree Architecture for DSP applications
Abstract— Wireless communication exhibits the highest energy consumption in wireless sensor network (WSN) nodes. Due to their limited energy supply from batteries, the low power design have become inevitable part of today’s wireless devices. Power has become a burning issue in VLSI design. In modern integrated circuits, the power consumed by clocking gradually takes a dominant part. Reducing the power consumption not only enhance battery life but also avoid overheating problem. By employing a more appropriate Processing Element (PE), the power consumption is significantly reduced. In this paper the novel method for low power design is achieved by using Folded Tree Architecture (FTA) and high speed adder design for on-the-node data processing in wireless sensor networks using Parallel Prefix Operations (PPO) and data locality in hardware. Besides power reduction the objective of minimizing area and delay is also considered.
Index Terms— Folded Tree Architecture (FTA), Parallel Prefix Operation (PPO), Processing Element (PE), Wireless Sensor Network (WSN).
- INTRODUCTION
Power optimization is always one of the most important design objectives in modern nanometer integrated circuit design. Especially for wireless sensor networks (WSNs), power optimization have become inevitable part in today VLSI design. Power optimization not only can enhance battery life but also reduce the overheating problem.
Self-configuring wireless sensor networks can be invaluable in many civil and military applications for collecting, processing, and disseminating wide ranges of complex environmental data. Because of this, they have attracted considerable research attention in last years. Sensor nodes are battery driven and hence operate on an extremely frugal energy budget. Further, they must have a lifetime on the order of months to years. Since battery replacement is not an option for networks with thousands of physically embedded nodes. In some cases, these networks may be required to operate solely on energy scavenged from the environment through seismic, photovoltaic or thermal conversion. This transforms energy consumption into the most important factor that determines sensor node lifetime.
The another important application in wireless sensor networks is event tracking, which has widespread use in applications such as security surveillance and wildlife habitat monitoring. Tracking involves a significant amount of collaboration between individual sensors to perform complex
signal processing algorithms such as kalman filtering, Bayesian data fusion and coherent beamforming. This applications will require more energy for their processing.
In general Wireless Sensor Networks (WSNs) can operate in four distinct mode of operation: Transmit, Receive, Idle and Sleep. An important observation in the case of most radios is that operating in Idle mode results in significantly high power consumption, almost equal to the power consumed in the Receive mode. The data-driven nature of WSN applications requires a specific low power data processing approach. By employing more appropriate Processing Element (PE), the power consumption in all the four mode of operation will be reduced significantly.

In present VLSI technology, reducing power consumption is an important issue. Especially for WSN, due to their limited battery lifetime the low power VLSI design is become inevitable for wireless commmunication. The goal of this paper is to design an low-energy Folded Tree and Multi-Bit Flip-Flop Merging technique for WSN nodes.
II. RELATED WORKS
In paper [2], the author proposed low-energy data processing architecture for WSN nodes using folded tree method. This paper identifies that many WSN applications employ algorithms which can be solved by using parallel prefix-sums. Therefore, an alternative architecture is proposed to calculated them energy-efficiently. It consists of several parallel Processing Elements (PEs) structured as a folded tree. The folded tree method with parallel prefix operations reduces the number of processing element and memory bottleneck. Due to clock distribution for more flip-flops, it consumes more clock power and also parallel prefix operations has high delay.
In paper [3], a novel method is proposed for low clock power consumption in WSN nodes. A previously derived clock energy model is briefly reviewed while a comprehensive framework for the estimation of system wide (chip level) and clock sub-system power as function of technology scaling is presented. This framework is used to study and quantify the impact that various intensifying concerns associated with scaling will have on clock energy and their relative impact on the overall system energy. This technology scaling method reduces power clock power consumption (both static and dynamic), but due to large number of processing element- area, inverter chain, Power-Delay Product is increased.
III. PROPOSED SCHEME
Folded Tree Architecture with Parallel Prefix Operation is used to reduce the total number of Processing Elements (PEs) in the VLSI design. By reducing the number of processing elements, the total area is reduced. Area is proportional to power, so power consumption is also reduced. During processing and transmission of signals, the WSN nodes will consume more power. Especially for clock distribution nearly 70% power will be consumed. In order to optimize the power during clock distribution, multi-bit flip-flop merging technique is used.
A. Folded Tree Architecture
A straightforward binary tree implementation of Blelloch’s approach costs a significant amount of area as n inputs require p = n − 1 PEs. To reduce area and power, pipelining can be traded for throughput. With a classic binary tree, as soon as a layer of PEs finishes processing, the results are passed on and new calculations can already recommence independently [8].

Fig 1. Binary tree equivalent to folded tree
The idea presented here is to fold the tree back onto itself to maximally reuse the PEs. In doing so, p becomes proportional to n/2 and the area is cut in half. Area is proportional to power, so power is also cut in half. Note that also the interconnect is reduced. This folded tree topology is depicted in Fig. 1, which is functionally equivalent to the binary tree on the left. By using the Folded Tree architecture power consumption, area and wirelength is reduced considerably. Folded Tree Architecture (FTA) for on-the-node data processing in wireless sensor networks, using parallel preï¬x operations and data locality in hardware reduces both area and power consumption.
TABLE I
LEAKAGE POWER AND DYNAMIC ENERGY FOR ONE PE UNDER NORMAL CONDITIONS

FTA is designed to reuse the PE nodes to reduces half of the total area. It limiting the data set by preprocessing with parallel preï¬x operations. The combination of data flow and control flow elements to introduce a local distributed memory, which removes the memory bottleneck while retaining sufï¬cient flexibility. Several processing element consumes more power, so by using FTA the PE can be reused and power is reduced.

Fig 2. Folding Architecture
In folding architecture, we can reuse the PEs with the help of counter and FSM. Iteration count in the counter contains the total number of times the specified PE going to be reused. The FSM enables and reset the iteration count based on the instructions.
B. Parallel prefix adder.
Adders are also very important component in digital systems because of their extensive use in other basic digital operations such as subtraction, multiplication and division. Hence, improving performance of the digital adder would greatly advance the execution of binary operations inside a circuit compromised of such blocks. The performance of a digital circuit block is gauged by analyzing its power dissipation, layout area and its operating speed.
The main idea behind parallel prefix addition is an attempt to generate all incoming carries in parallel and avoid waiting until the correct carry propagates from the stage of the adder where it has been generated.Parallel prefix adders are constructed out of fundamental carry operators denoted by ¢ as follows (G”, P”) ¢ (G’, P’) = (G”+G’·P”, P’·P”) where P” and P’ indicate the propagations, G” and G’ indicate the generations. The fundamental carry operator is represented as Figure

Fig 3. Carry operator
A parallel prefix adder can be represented as a parallel prefix graph consisting of carry operator nodes. The parallel prefix Ladner Fischer adder structure has minimum logic depth, but has large fan-out requirement up to n/2. Ladner Fischer adder has less number of delay compared to other parallel prefix adders. Power Delay Product should be less inorder to achieve high throughput and speed.
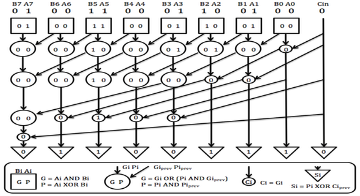
Fig 4. Ladner Fischer Parallel Prefix Adder
The Ladner Fischer adder construct a circuit that computes the prefix sums in the circuit, each node performs an addition of two numbers. With their construction, one can choose a tradeoff between the circuit depth and the number of nodes.
V CONCLUSION
This paper presented the Folded Tree Architecture and Multi-Bit Flip-Flop Merging technique for WSN applications. The design describes many data processing algorithms for WSN applications along with parallel prefix operations and clock distribution networks. Power is saved using flip flop merging technique by providing single clock signal to mergeable flip flops with the help of combinational lookup table. Thus this technique can be effectively used for clock distribution in integrated circuits requiring low power consumption in clock distribution network and low skew clocks. Area is reduced using folded tree architecture by reusing processing element. Ladner Fischer parallel prefix adder reduces the delay constraints and achieve high throughput. The proposed architecture significantly reduces both power and area in WSN nodes, can save up to half of the power in total sensor node.
REFERENCES
- V. Raghunathan, C. Schurgers, S. Park, and M. B. Srivastava,
“Energy-aware wireless microsensor networks,” IEEE Signal
Process.Mag., vol. 19, no. 2, pp. 40–50, Mar. 2002.
- C. Walravens and W. Dehaene, “Design of a low-energy data
processing architecture for wsn nodes,” in Proc. Design, Automat.
Test Eur. Conf. Exhibit., Mar. 2012, pp. 570–573.
- D. Duarte, V. Narayanan, and M. J. Irwin, “Impact of technology
scaling in the clock power,” in Proc. IEEE VLSI Comput. Soc.
Annu. Symp.,Pittsburgh, PA, Apr. 2002, pp. 52–57.
- H. Kawagachi and T. Sakurai, “A reduced clock-swing flip-flop
(RCSFF)for 63% clock power reduction,” in VLSI Circuits Dig.
Tech. Papers Symp., Jun. 1997, pp. 97–98.
- Y. Cheon, P.-H. Ho, A. B. Kahng, S. Reda, and Q. Wang, “Power-
aware placement,” in Proc. Design Autom. Conf., Jun. 2005, pp.
795–800.
- Y.-T. Chang, C.-C. Hsu, P.-H. Lin, Y.-W. Tsai, and S.-F. Chen,
“Post-placement power optimization with multi-bit flip-flops,”
in Proc.IEEE/ACM Comput.-Aided Design Int. Conf., San
Jose, CA, Nov. 2010,pp. 218–223.
- P. Sanders and J. Traff, “Parallel prefix (scan) algorithms for MPI,”
in proc, Recent ADV. Parallel Virtual Mach Message Pass, Interf.,
2006, pp.49-57.
- G. Blelloch, “Scans as primitive parallel operations,” IEEE Trans.
Comput.,Vol.38, no 11, pp. 1526-1538, Nov. 1989.
- D. B. Hoang, N. Kamyabpour “An Energy Driven Architecture for
Wireless Sensor Networks” International Conference on parallel
and Distributed computing Applications and technologies., Dec
2012.
- Nazhandali, M. Minuth, and T. Austin, “SensBench:Toward an
accurate evaluation of sensor network processors,”in Proc. IEEE
Workload Characterizat. Symp., Oct. 2005.
- M. Hempstead, D. Brooks, and G. Wei,” An accelerator-based
wireless sensor network processor in 130 nm cmos,” J, Emerg.
Select. Topics Circuits Syst., vol. 1, no. 2, pp. 193-202, 2011.
- B. A. Warneke and K. S. J. Pister, “An ultra-low energy micro-
controller for smart dust wireless sensor networks,” in Proc. IEEE
Int.Solid-state circuits conf. Dig. Tech. Papers. Feb. 2004,
pp. 316-317.
- M. Hempstead, M. Welsh, and D.Brooks,”Tinybench: The case for
a standardized benchmark suite for TinyOS based wireless sensor
network devices,” in Proc. IEEE 29th Local comout. Netw, conf.,
Nov.2004, pp. 585-586.
- O. Girard. (2010). “OpenMSP430 processor core, available at
opencores.org,” [online]. Available: http://opencores.org/project,
openmsp430.
- H. Stone, “Parallel processing with the perfect shuffle,” IEEE Trans.
Comput., vol. 100, no.2, pp. 153-161, Feb. 1971.
- M. Hempstead, J. M. Lyons, D. Brooks, and G-Y. Wei,” Survey of
hardware systems for wireless sensor networks,” J. Low Power
Electron., vol.4, no. 1, pp. 11-29, 2008.
- C.C. Yu. Design of low-power double edge-triggered flip-flop circuit.
In IEEE Conference on Industrial Electronics and Applications, pp.
2054-2057, 2007.
- M. Donno, A. Ivaldi, L. Benini, and E. Macii. Clock tree power
optimization based on RTL clock-gating. In Design Automation
Conference, pp. 622-627, 2003.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


DMCA / Removal Request
If you are the original writer of this essay and no longer wish to have your work published on UKEssays.com then please click the following link to email our support team:
Request essay removal